해시태그로 알아본 건설사 인기도 전처리
먼저 건설사에 대한 정보를 가져오기위하여 2022년 도급순위파일을 가져왔다.
https://www.worker.co.kr/link/2002R100.asp
해당파일은 다음과 같이 상호, 대표자, 소재지, 전화번호부터 각각 어떻게 도급순위가 평가되었는지를 알수있는 파일이다.
인기도를 확인하려면 역시 상호만 필요하다.
여기서 고민이 생겼다.
주식회사, (주)ㅁㅁ건설, ㅁㅁ건설(주) 등 주식회사임을 나타내는 순서가 각 회사마다 다양하다..
-> 결국 알아주는건 대표적인 브랜드이지 않을까 싶기도하고, 따라서 주식회사, (주) 등은 다 빼버리고 이후 이름이 중복되는건 더 유명한 회사의 게시글이지 않을까 싶어서 중복은 제거해버린다.

위와같은 엑셀자료를 불러오면 다음과 같이 순서가 너무 뒤죽박죽이되어버린다.
편하게하려면 역시 엑셀을 이용하여 셀 병합이 되어있는 부분을 제거하고 진행하면 되겠지만..
단순히 가져올 데이터가 건설사 이름뿐이니 그냥 진행한다.
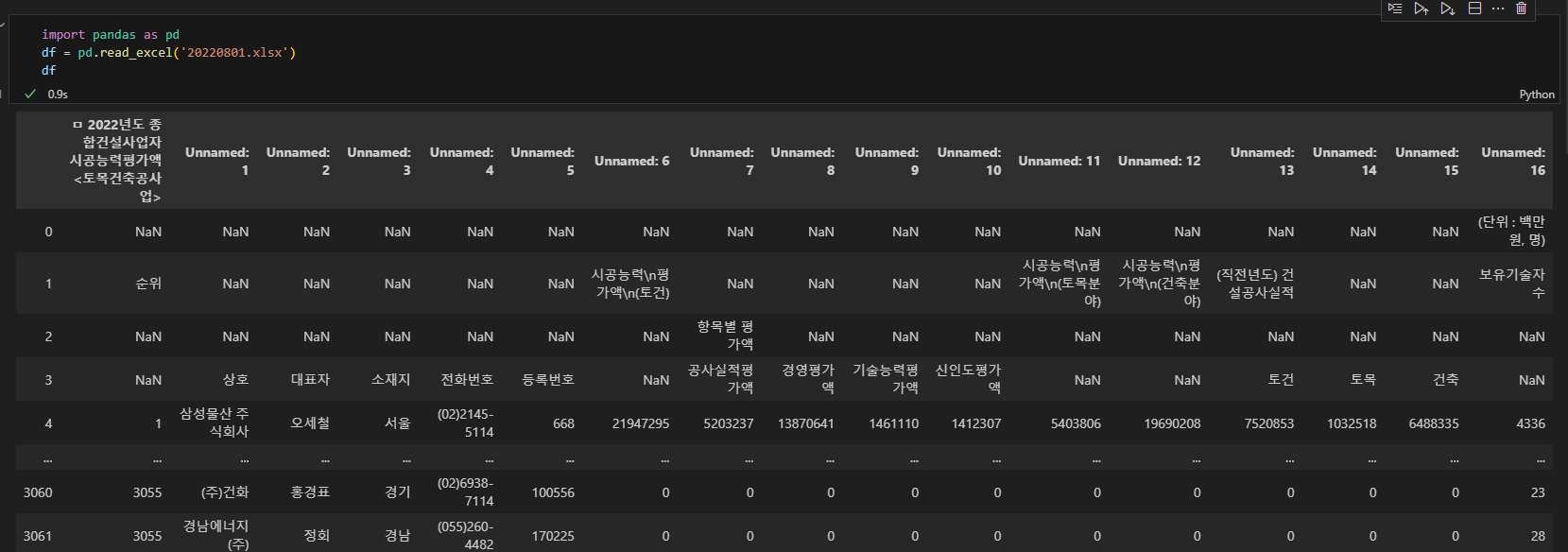
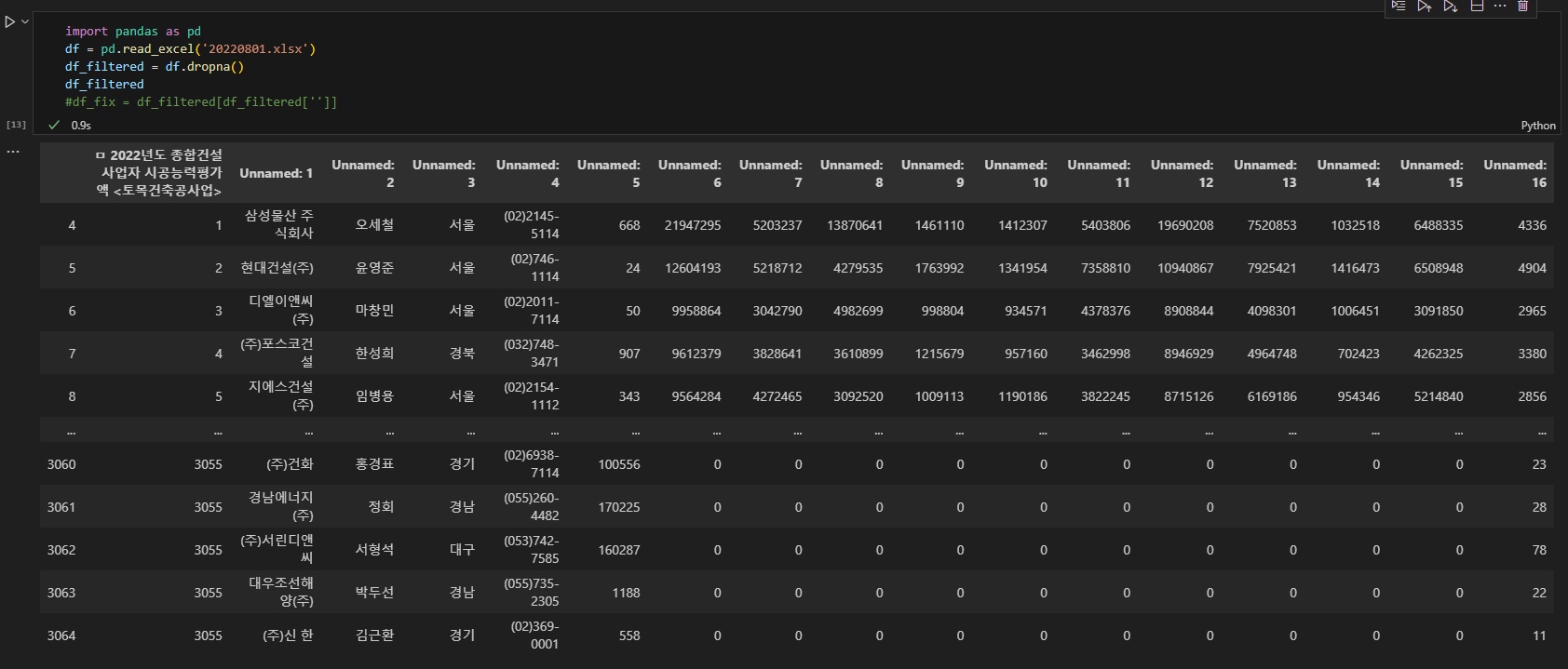
df.dropna()를 이용하여 결측치를 먼저 제거한다.
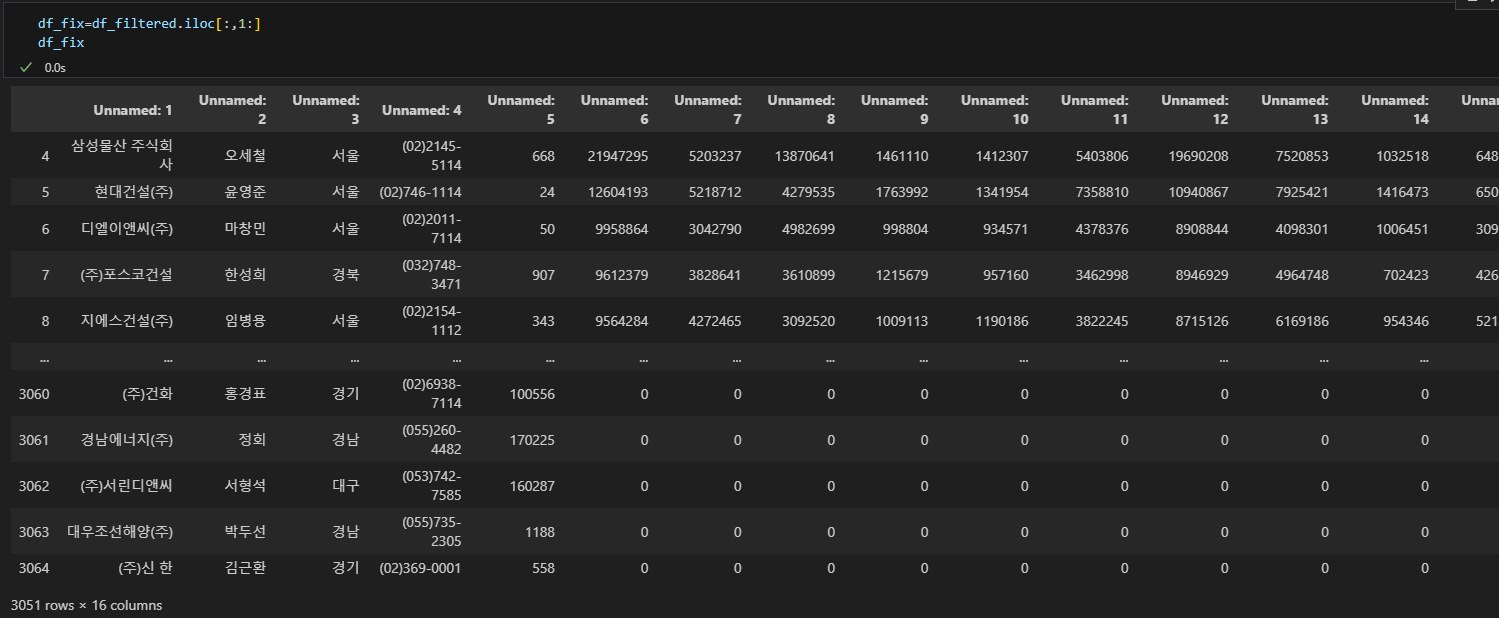
이후 순위를 날려버리려다가 그냥 뒤에도 다 날려버렸다
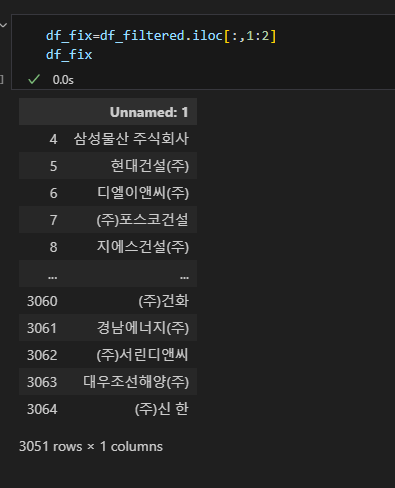
여기서 이제 컬럼명을 수정해주고, (주), 주식회사, 그리고 띄워져있는 부분을 다 제거한다.
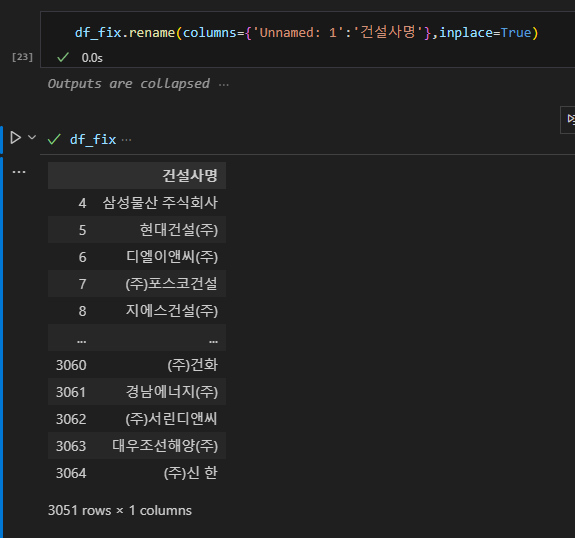
살짝 하드코딩스럽다.

이렇게 일단 전처리를 해보았다.
급 생각난 인덱스도 초기화 해준다.
drop=True를 해줘야지 기존 인덱스 위치에 대체하기에, drop을 해주어야하고,
inplace를 하지 않으려면 df_fix=df_fix(drop=True)를 해야하는데 굳이,,? 그냥 inplace=True를 넣어준다.
근데 마지막에 있는 신한은 어떻게 하지..?
이름은 이런 이유로 인기도 산정하는데 한계가 있는 것 같다.
